Make an AI model a five-star GTA player, here comes Octopus, a vision-based programmable intelligence

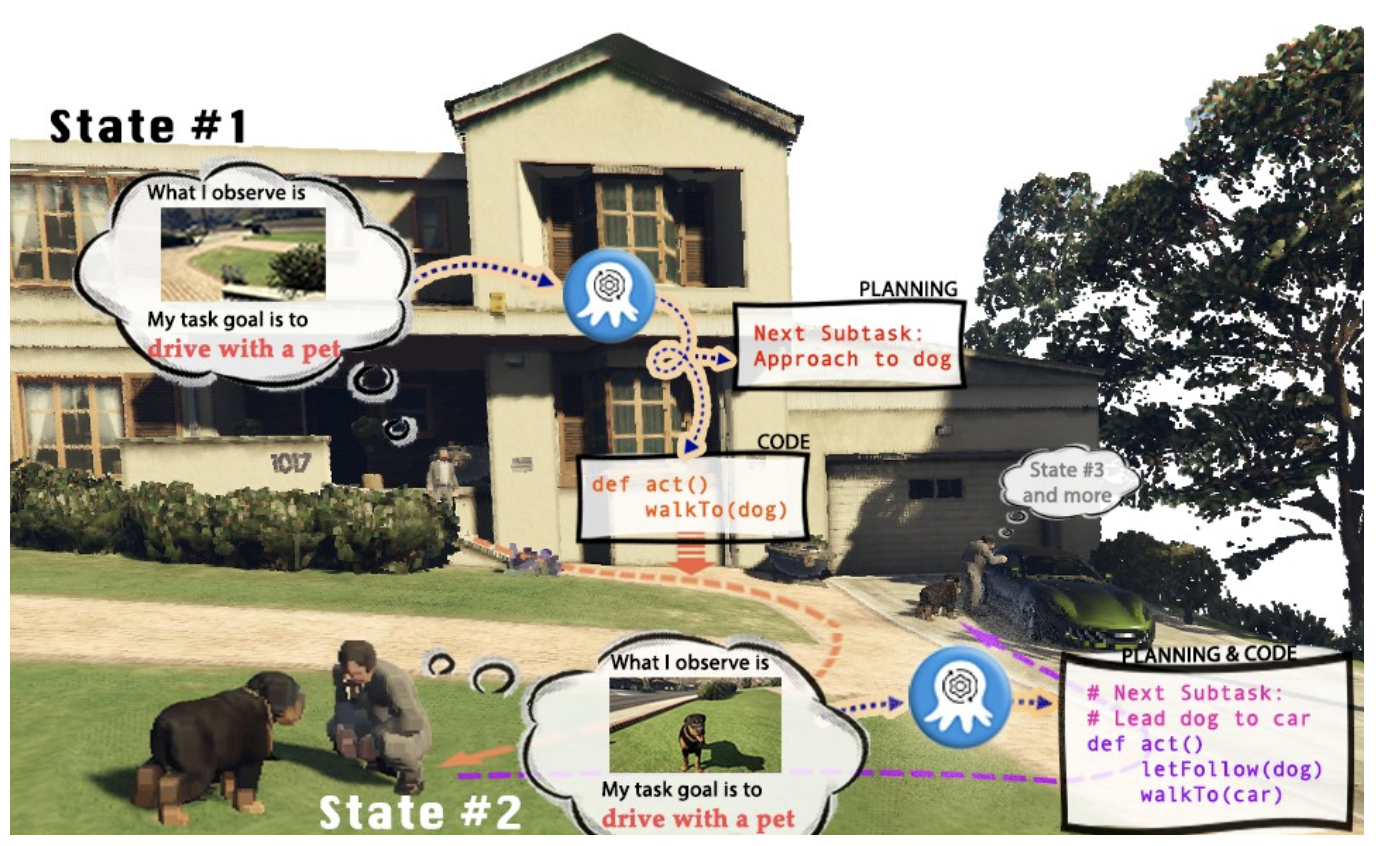
Video games have become a real-world analog of today's world, with endless possibilities. Take the game Grand Theft Auto (GTA) for example, in the world of GTA, the player can experience a colorful life in L.A. (the game's virtual city) from a first-person perspective. However, since human players can roam around L.A. and complete a number of missions, can we also have an AI visual model that can manipulate the characters in GTA and become the "players" who carry out the missions, and can the AI players in GTA play the role of a five-star good citizen, obey the rules of the road, help the police catch criminals, or even be a warm-hearted passerby? Can GTA's AI players play the role of a five-star good citizen, obey traffic rules, help the police catch criminals, or even be a warm-hearted passerby to help the homeless find proper shelter?
Current visual-linguistic models (VLMs) have made substantial progress in multimodal perception and reasoning, but they are often based on simple visual question and answer (VQA) or visual caption tasks. These task settings obviously do not allow VLMs to accomplish real-world tasks. Real-world tasks require not only an understanding of visual information, but also the ability of the model to reason about planning and to provide feedback based on real-time updates of the environment. The generated plans also need to be able to manipulate the entities in the environment to accomplish the task realistically.
Although existing language models (LLMs) are able to plan tasks based on the information provided, their inability to understand visual inputs greatly limits the scope of application of LLMs for real-world tasks, especially for embodied intelligence tasks where text-based inputs are often difficult to detail or too complex for the LLMs to efficiently extract information to accomplish the task. This makes the language model unable to efficiently extract information from it to accomplish the task. While current language models have been explored for program generation, the exploration of generating structured, executable, and robust code based on visual input has not yet advanced.
In order to address the problem of making macromodels intelligent, and to create autonomous and context-aware systems that can accurately plan and execute commands, scholars from Nanyang Technological University (NTU), Tsinghua University (TU), and other universities have proposed Octopus, a vision-based programmable intelligence that aims to learn from visual inputs, comprehend the real world, and generate executable code to accomplish a variety of real-world tasks. Octopus is a vision-based programmable intelligence that aims to learn from visual inputs, understand the real world, and accomplish various practical tasks by generating executable code. Trained on a large number of pairs of visual inputs and executable code, Octopus learns how to manipulate video game characters to complete gaming tasks or perform complex household activities.
Data Acquisition and Training
In order to train a visual-linguistic model capable of performing embodied intelligence tasks, the researchers also developed OctoVerse, which consists of two simulation systems to provide training data for Octopus training as well as a test environment. These two simulation environments provide usable training and testing scenarios for embodied intelligence of the VLM, and place higher demands on the model's reasoning and task planning capabilities. The details are as follows:
-
OctoGibson: Based on OmniGibson developed by Stanford University, a total of 476 real-life household activities are included. The simulation environment includes 16 different types of home scenarios, covering 155 real-life examples of home environments. The model can manipulate the large number of interactive objects present to accomplish the final task.
-
OctoGTA: Based on the Grand Theft Auto (GTA) game, a total of 20 missions were constructed and generalized to five different scenarios. A predefined program sets the player in a fixed location and provides the necessary items and NPCs to complete the mission to ensure that it goes smoothly.
The following figure shows the OctoGibson mission categorization and some statistics of OctoGibson and OctoGTA.

In order to efficiently collect training data in the two simulation environments constructed, the researchers built a complete data collection system. By introducing GPT-4 as the executor of the task, the researchers use a preimplemented function to process the visual inputs collected in the simulation environments into textual information and provide it to GPT-4. After GPT-4 returns the task plan and executable code of the current step, the researchers execute the code in the simulation environments and judge whether the task of the current step is completed or not. If it succeeds, it will continue to collect the visual input of the next step; if it fails, it will go back to the starting position of the previous step and collect data again.
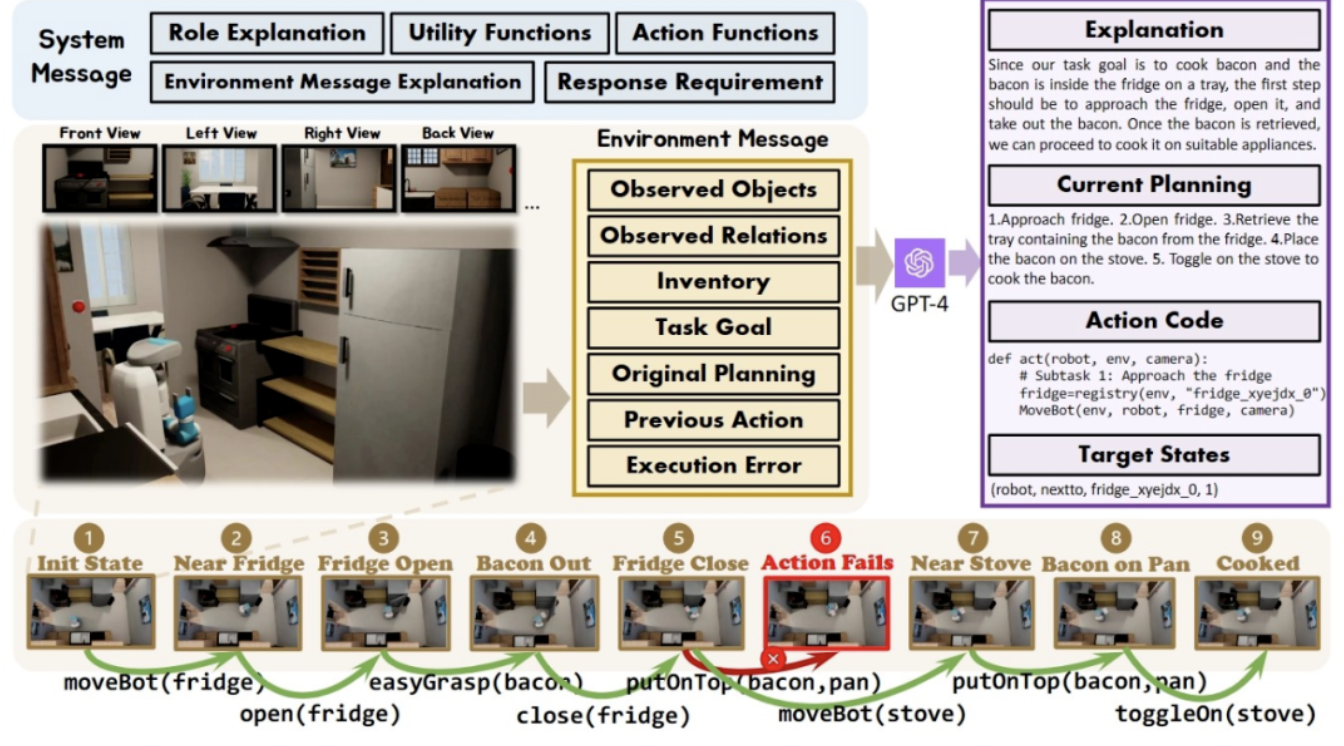
The figure above shows the complete process of data collection using the Cook a Bacon task in the OctoGibson environment as an example. It should be noted that during the data collection process, the researcher not only recorded the visual information during the execution of the task, the executable code returned by GPT-4, etc., but also the success of each sub-task, which will be used as the basis for the subsequent introduction of reinforcement learning to build more efficient VLMs.GPT-4 is powerful, but it is not infallible. Errors can manifest themselves in a variety of ways, including grammatical errors and physical challenges in the simulator. For example, as shown in Figure 3, between states #5 and #6, the action "put bacon in pan" fails because the distance between the bacon the agent is holding and the pan is too far. Such a failure resets the task to the previous state. If a task is not completed after 10 steps, it is deemed unsuccessful, we terminate the task due to budgetary concerns, and all pairs of data for all subtasks of this task are considered execution failures.
Experimental Results
The researcher tested the current mainstream VLM and LLM in the constructed OctoGibson environment, and the following table shows the main experimental results. For the different models tested, the Vision Model lists the visual models used for the different models, and for LLM, the researcher processed the visual information as text as the input to the LLM. For the LLM, the researcher processed the visual information as text as input to the LLM, where O provides information about the interactable objects in the scene, R provides information about the relative relationships of the objects in the scene, and GT uses true and accurate information without introducing additional visual models for detection.
For all test tasks, the researchers reported success rates for the complete test set and further divided them into four categories, recording the ability to generalize to new tasks in scenes present in the training set, to new tasks in scenes not present in the training set, and to simple following tasks as well as complex reasoning tasks. For each category of statistics, the researchers report two evaluation metrics, the first of which is the task completion rate, which measures the success of the model in completing the embodied intelligence task, and the second is the task planning accuracy, which is a measure of the model's ability to plan the task.
In addition, the researcher showed examples of how the different models responded to the visual data collected in the OctoGibson simulation environment. The figure below shows the responses generated by TAPA+CodeLLaMA, Octopus, and GPT-4V to the visual inputs in OctoGibson. It can be seen that the Octopus model trained with RLEF provides better task planning, even for the more ambiguous task instructions (find a carboy), than the TAPA+CodeLLaMA and Octopus models with only supervised fine-tuning. These results further demonstrate the effectiveness of the RLEF training strategy in improving the task planning and reasoning ability of the model.

Overall, there is still a lot of room for improvement in the actual task completion and task planning capabilities exhibited by the existing models in the simulation environment. The researchers summarized some key findings:
1. CodeLLaMA is able to improve the code generation capability of the model, but not the task planning capability.
The researchers pointed out that the experimental results show that CodeLLaMA can significantly improve the code generation ability of the model. Using CodeLLaMA resulted in better, more executable code than traditional LLM. However, although some models use CodeLLaMA for code generation, the overall task success rate is still limited by the task planning capability. Models with weaker task planning capability will still have lower task success rate even though the code generated has a higher executable rate; on the contrary, Octopus still has a better overall task success rate than other models due to its strong task planning capability, even though the executable rate of the code is reduced without the use of CodeLLaMA.
2. LLM is difficult to deal with a large amount of textual information input.
In the actual testing process, the researchers came to the conclusion that the language model is difficult to handle long text inputs by comparing the experimental results of TAPA and CodeLLaMA. The researchers followed TAPA's approach and used real object information for task planning, while CodeLLaMA used relative positional relationships between objects and objects in order to provide more complete information. However, during the experiments, the researchers found that due to the large amount of redundant information in the environment, when the environment is more complex and the text input increases significantly, it is difficult for LLM to extract valuable clues from the large amount of redundant information, which reduces the success rate of the task. This also shows the limitation of LLM, i.e., if textual information is used to represent a complex scene, a lot of redundant and worthless input information will be generated.
3. Octopus shows better task generalization ability.
It can be concluded from the experimental results that Octopus has strong task generalization ability. The success rate of Octopus in accomplishing tasks in new scenarios that do not appear in the training set and the success rate of Octopus in task planning are both better than those of the existing models. This also demonstrates some of the inherent advantages of vision-linguistic models, which generalize better than traditional LLMs for the same class of tasks.
4. RLEF can enhance the task planning ability of the model.
In the experimental results, the researchers provide a comparison of the performance of the model after only the first stage of supervised fine-tuning and after RLEF training. It can be seen that after RLEF training, the overall success rate and planning ability of the model is significantly improved for tasks that require strong reasoning and task planning ability. RLEF is also more efficient than the existing VLM training strategies. The example shown in the figure above also illustrates the improvement in the task planning ability of the model after RLEF training. After RLEF training, the model can know how to explore the environment when facing more complex tasks; moreover, the model can follow the actual requirements of the simulation environment (e.g., the model needs to move to the object to be interacted with before it can start the interaction) in task planning, thus reducing the failure rate of task planning.
Summarizing
The researchers have pointed out some limitations of the current work:
-
The current Octopus model does not perform satisfactorily on more complex tasks. When faced with complex tasks, Octopus tends to make incorrect planning and relies heavily on feedback from the environment, making it difficult to accomplish the overall task.
-
Octopus models are only trained in simulation environments, and there are a number of problems with migrating them to the real world. For example, it is difficult to get accurate information about the relative positions of objects in the real environment, and it becomes more difficult to build up an understanding of the scene.
-
Octopus' current visual inputs are discrete static images, how to make it able to handle continuous video will be a challenge in the future. Continuous video can further improve the performance of the model to accomplish the task, but how to efficiently process and understand the continuous visual input will be the key to further improve the performance of VLM.