Unveiling Unprecedented Excitement: Messi's Games and League of Legends Transformed by OpenAI GPT-4 Visual API!
Developers who have used the OpenAI Vision API have been amazed.
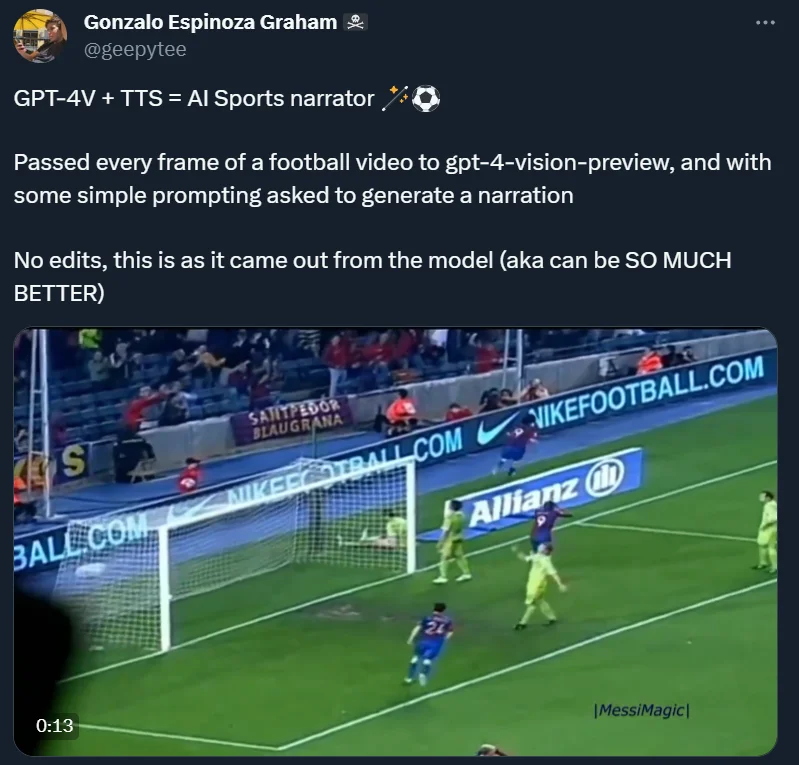
At the beginning of the article, let’s take a look at a game commentary video:
Doesn't it sound right?
You are right, because this commentary was generated by AI, and the voice shouting "Messi! Messi!" actually came from AI.
This is a video posted by Platform X (formerly Twitter) blogger @Gonzalo Espinoza Graham. He said that during the production process, he mainly used two technologies: GPT-4V and TTS.
GPT-4V is a large multi-modal model released by OpenAI some time ago. It can not only chat through text like the original ChatGPT, but also understand the images provided by users in the chat. What’s even more exciting is that at yesterday’s developer conference, OpenAI announced that they have opened an API related to vision capabilities—gpt-4-vision-preview. Through this API, developers can use OpenAI’s latest GPT-4 Turbo (visual version) to develop new applications.
Developers are eager to try this long-awaited API. Therefore, just one day after the API was opened, many developers posted trial results, and this football game commentary was one of them.
The blogger said that in order to make this commentary video, he passed the frames of the original video to gpt-4-vision-preview in batches, then asked the model to generate a narration through some simple prompts (prompt), and finally used TTS to get the results (Text-to-speech technology) converted into audio, you can get the effect shown in the video. With a little editing, you could theoretically get better results. According to OpenAI's current pricing, it costs about $30 to produce this video, which the author calls "not cheap."
Related code: https://github.com/ggoonnzzaallo/llm_experiments/blob/main/narrator.ipynb
In addition to football games, some developers also posted a demo of using the OpenAI visual API to explain "League of Legends". This demo used a video of a match between LNG and T1, which attracted the attention of more than 500,000 netizens on the entire network.
The explanation effect is as follows:
However, how to make this kind of video?
Fortunately, in addition to these finished product effects, some developers also posted tutorials they summarized and the specific tools involved in each step.
Starting from the content posted by X platform user @小互, the entire implementation process can be divided into 7 steps:
- Extract video frames;
- Build description prompt;
- Send a GPT request;
- Create voice commentary prompts;
- Generate voice commentary scripts;
- Convert script to audio;
- Combine audio with video.
However, someone raised a question in the comment area: These games are all from the past. Can real-time games be explained?
We still can’t tell whether the real-time game can be explained, but some developers did show a demo that uses the OpenAI Vision API to interpret camera content in real time:
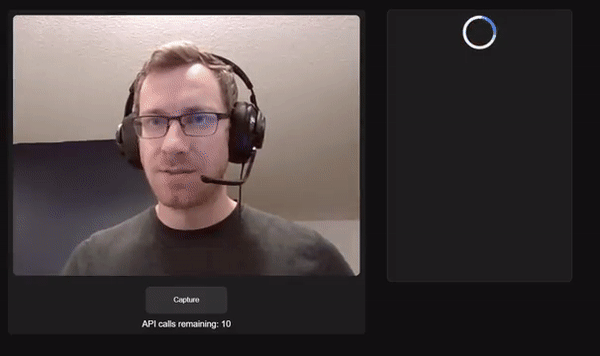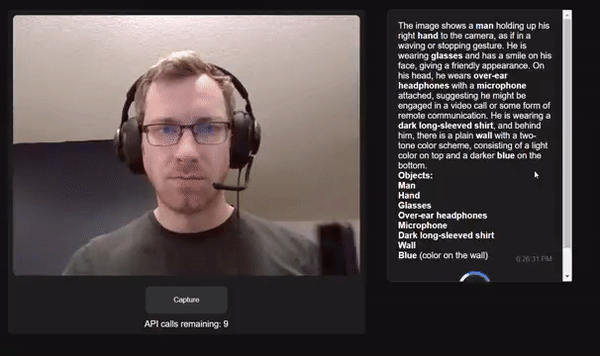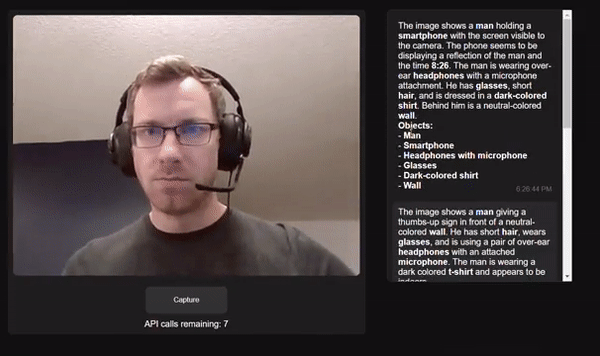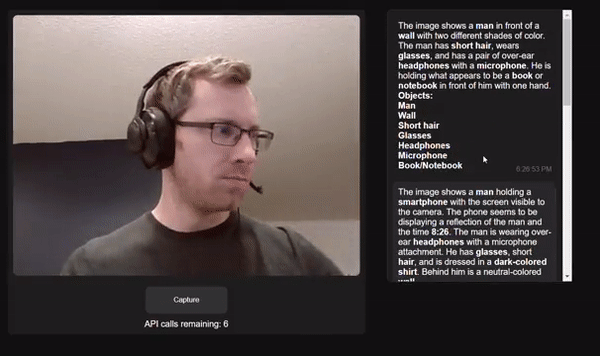
Project link: https://github.com/bdekraker/WebcamGPT-Vision
Developers who have conducted similar experiments commented that the recognition speed of OpenAI Vision API is very fast and the accuracy is also high.
Some people even use it directly as a real-time drawing tool, converting the sketch in their hand into a chart that could only be drawn by calling professional drawing tools in real time:

However, this experiment with real-time effects will be subject to rate limits set by OpenAI.
It can be said that OpenAI is letting the world see the power of multi-modality through GPT-4V and the newly opened visual API. The above effects are just the tip of the iceberg.
In fact, whether in real life or in the research field, an AI that can understand images and videos has a wide range of uses.
In life, it can be used to build more intelligent robots, allowing the robots to analyze the situation in front of them in real time and adapt to changes. This is also a problem that is currently being studied in the field of embodied intelligence.
In addition, it can also be used to improve the quality of life of the visually impaired and help them interpret video images and life scenes.
In a recent paper by Microsoft, researchers also demonstrated the progress they have made in this area, such as using GPT-4V to interpret the plot of "Mr. Bean".
This excellent video interpretation ability can help researchers better understand videos, thereby converting widespread videos into new training data, training smarter AI, and forming a closed loop.
It seems that a smarter world is accelerating.